While going through the “Nightly Anything Goes” thread in Reddit’s r/fantasybaseball, I noticed one user’s comment on the hivemind nature of the community and how every week there’s a new player that people won’t stop talking about. This got me thinking - who is the most talked about player in this community? This seemed to be a fun question worth exploring, while giving me some exposure to scraping from Reddit and working with text analyses.
I started off by exploring my different options for how to extract the data from Reddit. I came across a really cool package, RedditExtractoR that looked to be particularly useful for extracting the nested comments from Reddit.
Before I proceeded any farther, I also had to figure out the scope of this analysis. Would I be looking through every post throughout the history of this subreddit? What types of posts or comments would I be examining? Balancing these factors of making it meaningful but also not too time-consuming, I decided to analyze the comments from every “Daily Anything Goes” and “Nightly Anything Goes” threads of the current week (Week 5 of the season).
Next, I’ll start by going through the analysis, which, as always, begins with loading the necessary packages.
library(tidyverse)
library(tm)
library(qdap)
library(RedditExtractoR)
library(wordcloud)
library(wordcloud2)
I used the ‘reddit_content’ function from RedditExtractoR to scrape the r/fantasybaseball comments. Sadly, each URL contains a random string of characters, so I was unable to apply this function through a loop.
apr29_1 <- reddit_content("www.reddit.com/r/fantasybaseball/comments/bipdua/daily_anything_goes_april_29_2019")
# continued for rest of dates
df <- bind_rows(apr29_1, apr29_2, apr30_1, may1_1, may1_2, may2_1, may2_1, may2_2, may3_1, may3_2, may4_1,
may4_2, may5_1, may5_2) %>%
select(doc_id = id, text = comment, user) %>%
mutate(text = str_replace_all(text, "[^[:graph:]]", " "))
Next, I use this dataframe to create a clean corpus. Corpora are special documents containing text. The “tm” package includes convenience functions for cleaning the text in a corpus: putting text in lower case and removing white space, punctuation, and stop words (e.g. that, it, who).
source <- DataframeSource(df)
corpus <- VCorpus(source)
clean_corpus <- function(corpus){
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removeWords, stopwords("en"))
return(corpus)
}
clean_corpus <- clean_corpus(corpus)
The clean corpus is then transformed into a table containing the frequency of each word. Among the top words, there were several words that weren’t names, such as “fantasy”, so I had to manually go through and identify the top names and store these in the “names” vector.
tdm <- TermDocumentMatrix(clean_corpus)
comment_matrix <- as.matrix(tdm)
term_frequency <- rowSums(comment_matrix)
term_frequency <- sort(term_frequency, decreasing = T)
terms_vec <- as.vector(names(term_frequency))
wc_df <- data.frame(word = terms_vec, freq = term_frequency) %>%
filter(freq > 50)
names <- c("smith", "chavis", "paddack", "senzel", "lowe", "winker", "polanco", "robles",
"snell", "voit", "franmil", "yandy", "santana", "puig", "caleb", "glasnow",
"soroka", "nola", "trout", "joram", "votto", "harper", "kieboom", "shaw",
"vlad", "turner", "alonso", "marte", "segura", "boyd", "domingo", "weaver",
"degrom", "dozier")
Finally, I represent the frequency of each name with a wordcloud, built with the wordcloud package. In this visualization, the size of the word is positively related to its frequency. I also attempted using the “wordcloud2” package, but it seemed to be pretty buggy and difficult to work with.
wordcloud(names, term_frequency[names], colors = c("red", "blue"), scale = c(2, .25))
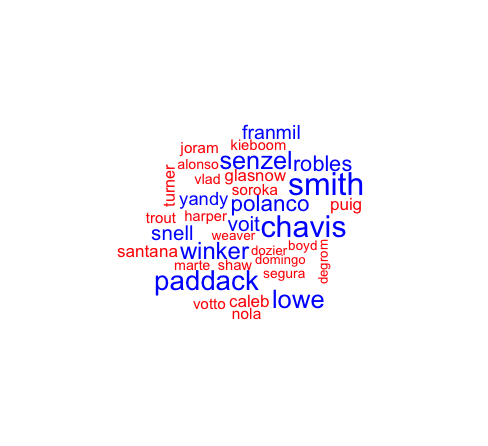
It appears that “Smith” was the most talked about player. As you can probably imagine, this doesn’t correspond to a single player. It could be in reference to a variety of different Smiths: Mallex, Caleb, Dominic, Will etc. Unfortnately, most of the Reddit comments don’t explicitly mention the first name; it is often implied with the rest of the context. Future work will have to consider methods of differentiating within common last names. For starters, the vocabulary in the comment should at least be able to indicate if the player is a batter or pitcher.
If you’d like to see the post and discussion on Reddit, check it out here.